get_iplayer Forums blog
NOTICES | ANNOUNCEMENTS | UPDATES
-
BBC kills live streaming feeds - EDIT - restored in v2.93
categories: [ Announcements ]
 They're on a roll!
They're on a roll!EDIT - v2.93 returns live streaming functionality
Not content with just killing the ION feeds, the BBC has also removed the resources get_iplayer relies on to stream live TV.
get_iplayer maintainer dinkypumpkin states:
This problem is indicated by the following error messages:
If you can't quite believe it, read the same thing again in a forum post here.ERROR: Failed to get version pid metadata from iplayer site ERROR: Could not get version pid metadata
There is no workaround and no prognosis on when or if live TV streaming will be restored.
So, for now, that's all folks!
-
BBC iplayer blows up TV listing feeds - Radio survives for now
categories: [ Announcements ]
As the BBC marches ever onwards toward launching their new Nitro API they are slowly but surely shutting down the various feeds used by apps like get_iplayer to obtain relevant programme listings.
Today, the BBC has shut down the feeds currently being used by get_iplayer to obtain TV listings meaning users will now see multiple
WARNING: Failed to get programme index feedwarnings whilst attempting to update their TV Cache.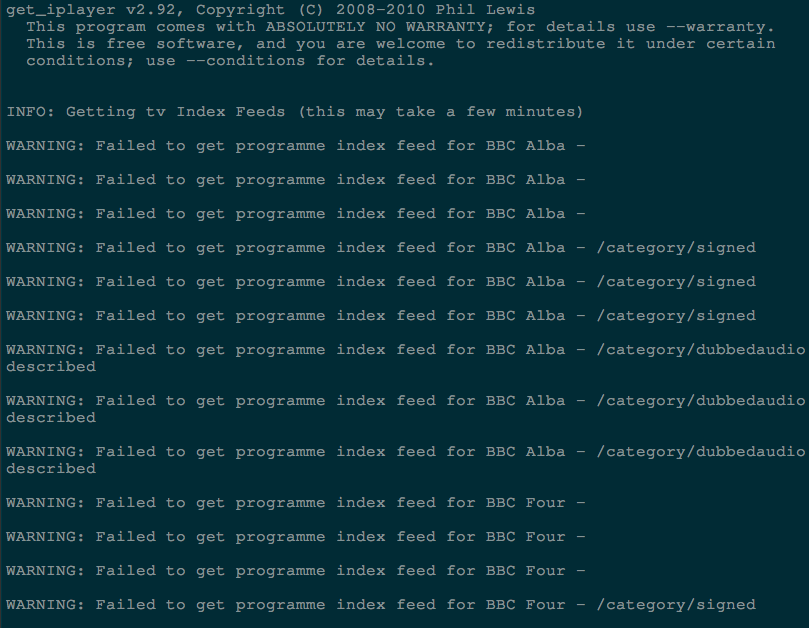
The good news is there is a workaround for this issue that you can implement immediately (thanks to the hard work of get_iplayer maintainer dinkypumpkin).
A new version of get_iplayer is due to be released shortly that will enact this workaround more permanently - again thanks to the work of dinkypumpkin.
-
Support Requests: 3 tips for communicating with (some) open source projects
categories: [ Preachy ]
A recent forum post by a new poster raised an ember of inspiration in me regarding the issue of a new user communicating with an open source project.
Keen eyed readers will notice how I phrased that - a user communicating with an open source project...not the other way around, we're not going to be focusing on how a project 'should' communicate with users but what users can do to make their experience communicating with open source projects a little smoother.
I'm not in the habit of telling people what to write or say and I'm not going to set out a series of commandments that a user or project must follow, that's not the point of this blog post.
What I do want to do is offer users a few tips to help 'manage expectations' because communicating with an open source project can be very different to communicating with a paid or for profit entity.
1. Help yourself!
If you haven't googled your particular issue, read the documentation, scoured the forums, tracked down the address and driven to the house of that user back in 1998 who had the same issue but only saw fit to post a 'Problem resolved' message, and then subsequently beaten the answer out of them (I jest)...well then you're in for a bad time.
Nothing infuriates an open source project more than asking a question that has already been answered, sometimes many many times over, but you simply haven't taken the time to look it up. It's lazy, makes you look like an idiot and people will delight in telling you where to go.
Also remember, starting off by making yourself look like an idiot will shape future communication with you - see point one above.
Now, let me caveat that last sentence.
The fact people will think you're an idiot is one thing, actually being an idiot is another. For instance, how would you know to look up 'hyperdyne metafold generator failure is causing recursive extoplasmic segmentation faults'?
You wouldn't, and not knowing that doesn't make you an idiot.
But to people who do know that and have answered the same question 30 billion times you will look like one.
This is what is known as a 'no win situation'. Enjoy it! (The moral of the story being, try to relax let this wash over you like water off a ducks back, as there is nothing you can do about it.)
The second half to helping yourself is, after reading the documentation and confirming there is a real genuine problem, providing ALL the information necessary to replicate the issue. Actually, I'm going to stop right there. This point could fill a book in itself so let me instead defer to the excellent words of Simon Tatham and his How to Report Bugs Effectively essay.
That essay should be required reading. If there was a license all of us had to sit to even be allowed behind the keyboard of a computer I'd use my single vote for this being in the curriculum, if only for the hope that there might be a few less Mongooses in the world.
2. You are a user, not a customer
This is an absolutely fundamental difference that goes right to the heart of the matter. Many of us live in a world dominated by the US customer service model, where the customer is always right and their views are at least made to feel extremely important, even if they are silently ignored in practice!
This tends to carry over into the software world but here the practice becomes a little blurred.
-
categories: [ Updates ]
Thanks to the hard work of get_iplayer maintainer Dinkypumpkin get_iplayer has been updated to version 2.90 and contains fixes and workarounds for several issues get_iplayer has recently experienced, most notably the removal of programme feeds by the BBC.
Read the release notes!
This is an extensive update and you should read the release notes to get yourself up to speed.
Lets try that again...
READ THE RELEASE NOTES!!! Thank you!
Getting the latest update
Installation information can be found within the release notes. Windows users will need to use the latest installer and linux/unix users will need to use the manual installation method until updates are made to the packages that are maintained for you particular system.
Users guides and other info
With a big change like this it will take some time to get the guides hosted here up to speed. Bear with me as I get these done and if you have trouble in the meantime after reading the release notes, pop over to the forums and post you problem there where the community can help you.
-
BBC removes programme feeds - a blow to get_iplayer
categories: [ Announcements ]
Sad news - the BBC has today removed the feeds used by get_iplayer to download shows using the search or index number methods, which means you can no longer download programmes using two of the must useful methods get_iplayer provides.
Further, due to the loss of these feeds get_iplayer can no longer schedule programmes for download - in short the PVR is now broken.
Thankfully you are still able to download programmes manually using the PID or URL methods. Take a look at the TV Download Guide for a short guide on downloading using the PID method and dig into the documentation to see how to download using the URL method.
Other functionality such as the ability to specify output folders and other get_iplayer specific abilities are not affected as these are built into get_iplayer itself.
-
I'm sorry, I broke muscle memory!
categories: [ Maintenance ]

It's been about a year and a half since I threw this site together over a weekend. After all this time, some changes were needed. I know everyone hates change, particularly that which breaks muscle memory, but there were certain layout issues that needed to be addressed here on squarepenguin.co.uk.
- Firstly, the size of the header and footer 'wrappers' with that enormous menu, horrible logo and massive amounts of whitespace.
- Secondly, the proliferation of list style menus which are terrible for mobile users (who make up a statistically significant portion of traffic now).
- Thirdly, layout improvements to make knowing where you are in the site and information retrieval easier for new visitors and faster for frequent fliers.
-
Regarding Heartbleed, Shellshock and POODLE
categories: [ Maintenance ]
It's been a busy time for System Administrators over the last few weeks and months. Several high profile and critical vulnerabilities were discovered in very commonly used software, software that is also used here on squarepenguin.co.uk.
It's common practice to be open about these types of issue, usually on a faster timescale than I am able to commit to right now! But to cut a long story short and without getting into the technicalities, all relevant measures were taken to immediately patch these vulnerabilities and due the the particular way this website is setup, at no point was it actually vulnerable to them in the first place.
To that end, I can confirm squarepenguin.co.uk is not and has not been vulnerable to Heartbleed, Shellshock or the most recently announced POODLE vulnerabilities.